

W drugim artykule z serii Anatomia LLM sprawdzimy, jak zapanować nad kreatywnością dużego modelu językowego. Najpierw musimy zrozumieć, co dokładnie zwraca LLM i jaki sposób można zmodyfikować wynik jego działania.
Co zwraca model?
Jak wiemy, każdy tekst z perspektywy dużego modelu językowego jest sekwencją najmniejszych, niepodzielnych jednostek, zwanych tokenami. Unikatowy token to zwykle całe słowo lub krótszy ciąg znaków. Odsyłam tutaj do swojego poprzedniego artykułu, gdzie nieco obszerniej omawiam tę kwestię. Dla przypomnienia rzućmy okiem na prezentowane już na tej stronie przykłady podziału na tokeny dwóch tekstów: w języku polskim i angielskim. Jest to konkretnie tokenizacja według kryteriów używanych w Chacie GPT. Nie są one uniwersalne i mogą różnić się w zależności od modelu.
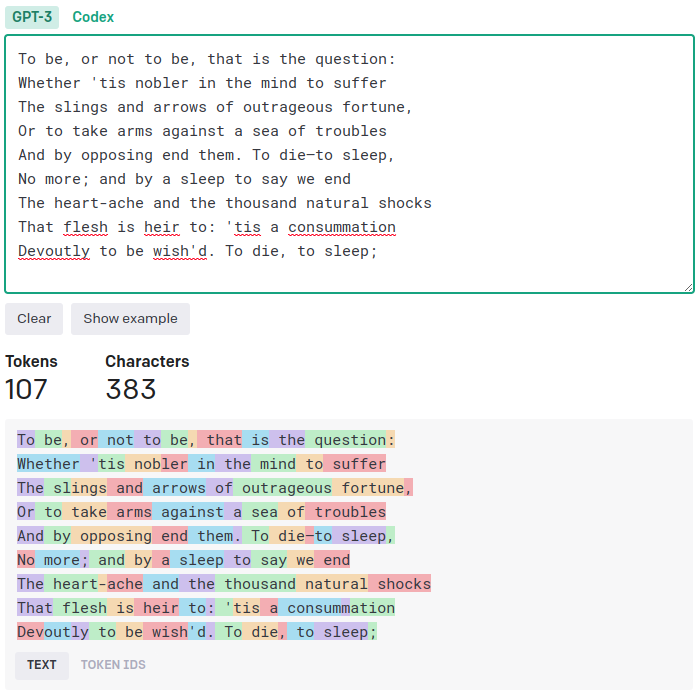
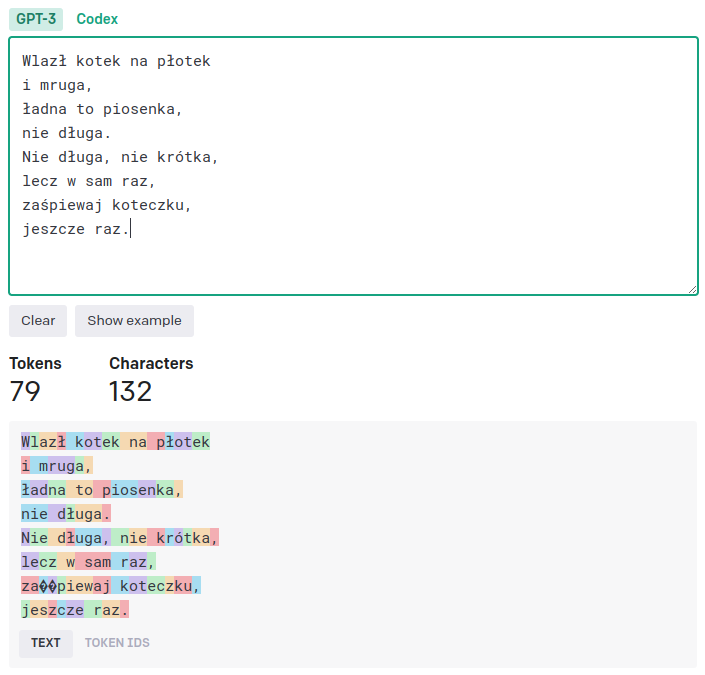
Jak widzimy, w świecie Chatu GPT występują m.in. takie tokeny jak “To“, ” be“, “Dev” czy też “ł” lub “uga“. Razem tworzą one stały, niezmienny słownik o określonej wielkości. Model może się posłużyć tylko takimi tokenami, które posiada w swoim słowniku. Liczba ta nie jest jednak mała i przeważnie dochodzi do kilkudziesięciu tysięcy unikatowych tokenów.
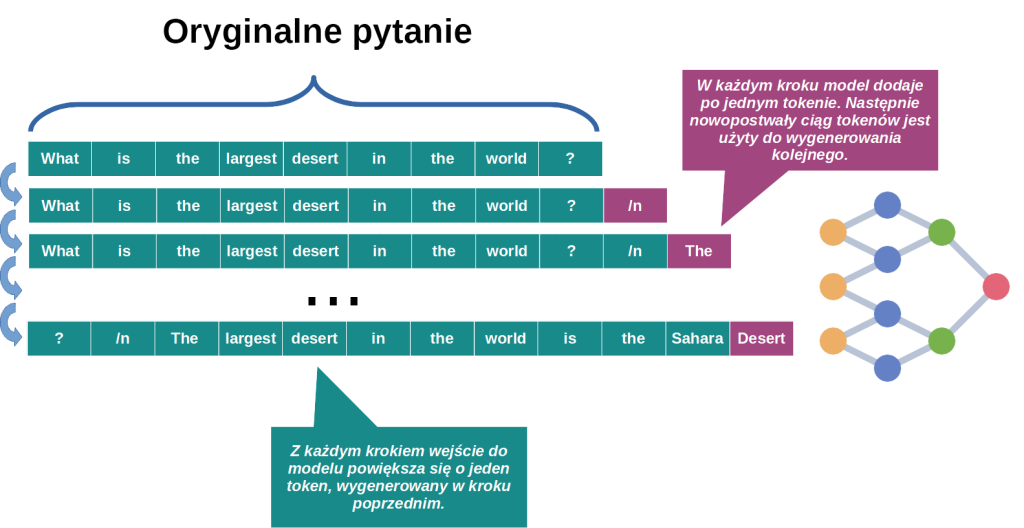
Jak też wspominałem w pierwszym artykule, przy konstruowaniu architektur dużych modeli językowych przyjęło się, że model zwraca tylko jeden token na raz. Oczywiście, my jako użytkownicy tego nie zauważamy, gdyż widzimy już całą wypowiedź modelu. W rzeczywistości jest ona generowana po kolei, token po tokenie. Najpierw model zgaduje pierwszy token, który jest doklejany do pierwotnego zapytania. Drugi token jest więc generowany częściowo także na podstawie poprzedniej odpowiedzi modelu. Trzeci powstanie rzecz jasna przy udziale pierwszego i drugiego, i tak dalej. Model o takiej charakterystyce nazywamy autoregresyjnym.
To czy autoregresyjne modele językowe są dobre czy też nie, jest kwestią dyskusyjną – zobacz np. krytyczną opinię znanej postaci ze świata AI, profesora Yanna LeCunna, zatrudnionego w Meta (LinkedIn, prezentacja). Nie będziemy tutaj roztrząsać tego zgadnienia, gdyż nadawałoby się ono na osobny wykład.
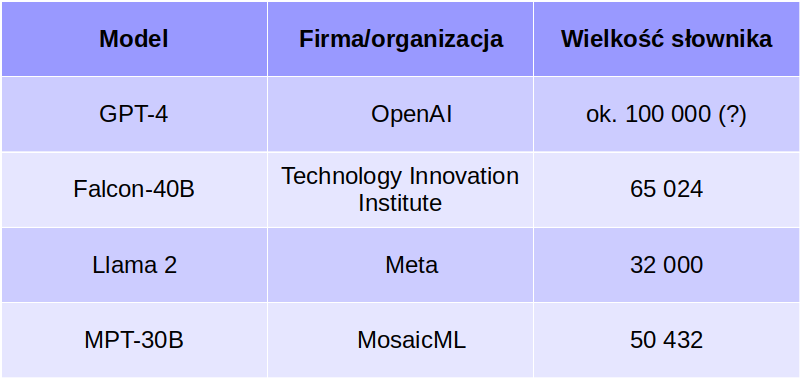
W jaki sposób model komunikuje nam, że właśnie ten konkretny token jest elementem najlepiej pasującym do układanki? Tym, co na końcu wychodzi z sieci neuronowej jest de facto rozkład prawdopodobieństwa dla wszystkich tokenów w słowniku. Innymi słowy, np. Falcon-40B zwróci tablicę 65 024 liczb, z których każda mieści się w zakresie od zera do jeden (wyłącznie) i razem sumują się do jedynki. Oczywiście przedział 0 do 1 to inaczej 0-100% (prawdopodobieństwa ujemne i większe niż 100% na ogół nie mają sensu).

Strategie dekodowania
Mając na wyjściu rozkład prawdopodobieństwa, możemy wygenerować token korzystając z wybranej strategii dekodowania. Najprostsza, znana jako podejście zachłanne (ang. greedy sampling), polega na wyborze odpowiedzi o największym prawdopodobieństwie. Efektem jest deterministyczne działanie modelu: dla danego promptu otrzymamy dokładnie tę samą odpowiedź.
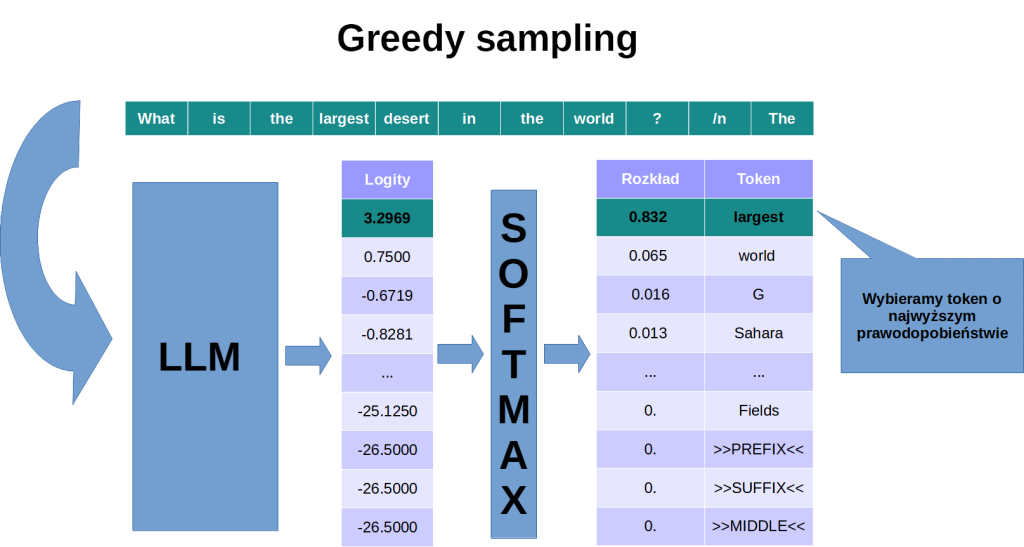
Aby dać modelowi trochę swobody wyboru, musimy wprowadzić czynnik losowy. W strategii zwanej samplingiem, token jest losowany zgodnie z rozkładem prawdopodbieństwa wyprodukowanym przez LLM. W przykładzie pokazanym na obrazku, dysproporcja między najbardziej prawdopodobnym tokenem a kolejnymi na liście jest na tyle duża, że i tak prawie zawsze wylosowalibyśmy token largest.
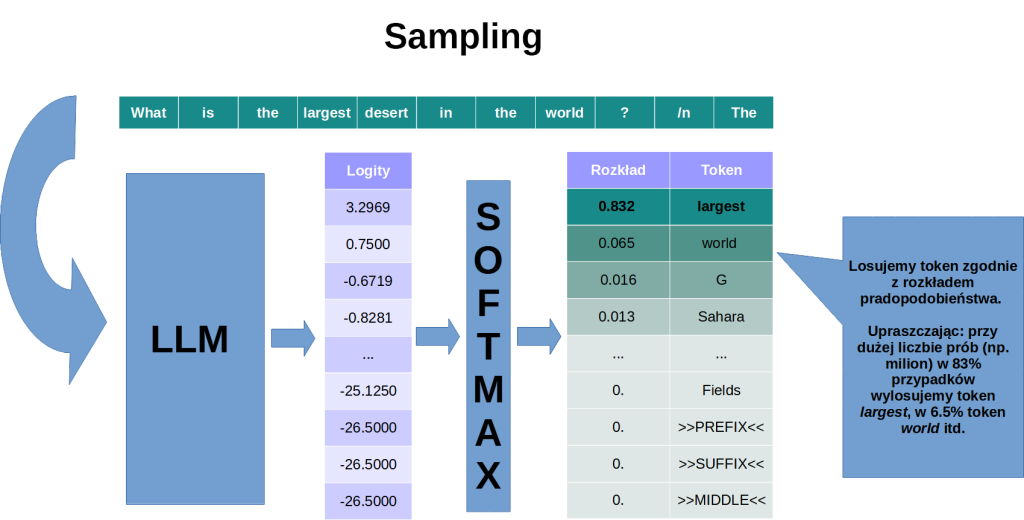
Aby móc efektywnie skorzystać z losowania tokenów, warto zastosować prostą sztuczkę polegającą na sterowaniu tzw. temperaturą.
Softmax
Żeby zrozumieć jak działa mechanizm sterowania temperaturą, musimy się najpierw przyjrzeć działaniu funkcji softmax. Jak sugeruje sama nazwa, funkcją softmax wskazuje na największą wartość w wektorze, ale w sposób “miękki”, tzn. nie zero-jedynkowy. Jej przeciwieństwem będzie funkcja – nazwijmy ją hardmax – która zwraca 1. tylko dla najwyższej wartości i zera we wszystkich pozostałych przypadkach.
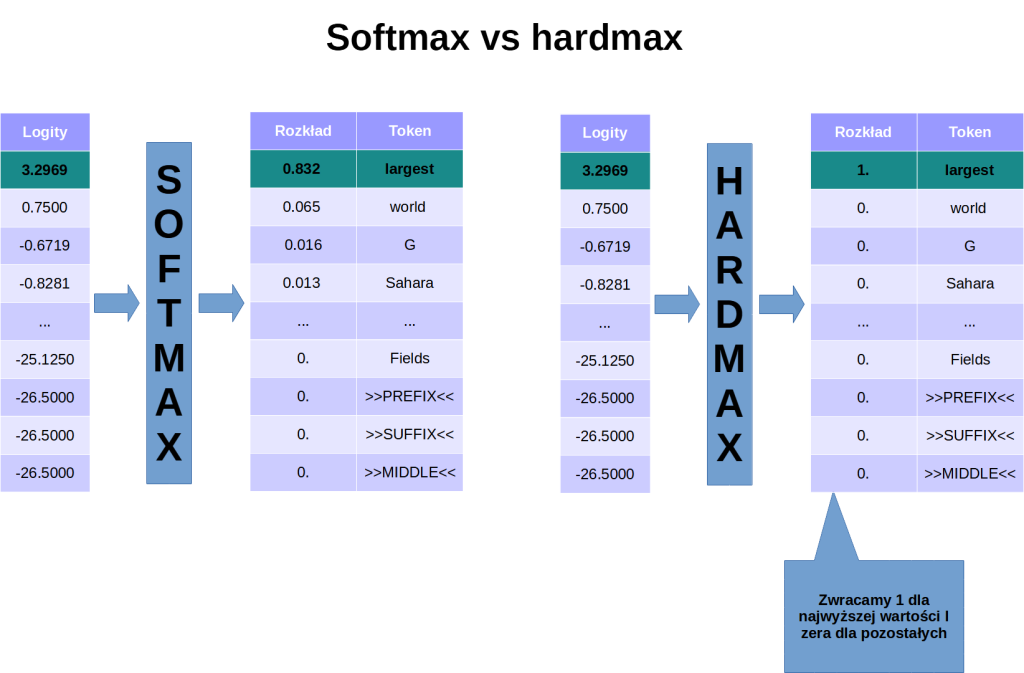
Dlaczego w ogóle używamy funkcji softmax zamiast argmax/hardmax? Po pierwsze, funkcja softmax jest różniczkowalna, co jest kluczowe w przypadku trenowania sieci neuronowych. Po drugie – chcemy uzyskać na końcu rozkład prawdopodobieństwa zamiast jednoznacznej odpowiedzi.
Dygresja a propos różniczkowalności: popularna w deep learningu funkcja ReLU nie jest rożniczkowalna na całej dziedzienie (brak wartości w punkcie zero). Obchodzimy ten problem, naginając zasady matematyki – większość implementacji udaje, że pochodna ReLU w zerze równa się zero (patrz np. PyTorch).
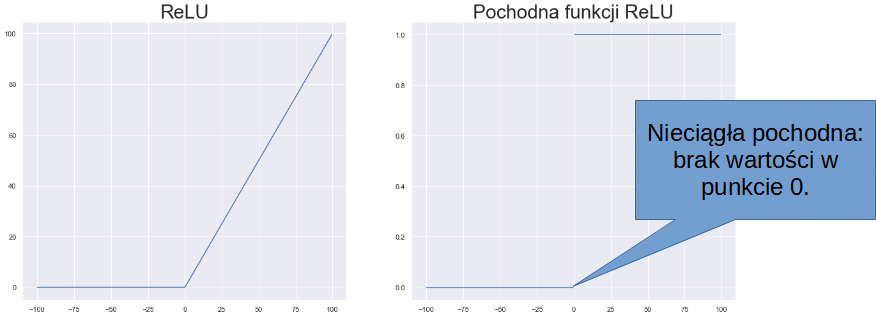
Sam rzut oka na te obrazki pozwala nam złapać pewną intuicję – gwałtowne “załamania” wykresu funkcji mogą skutkować nieciągłością pochodnej.
W funkcji softmax najpierw aplikujemy funkcję wykładniczą do wszystkich surowych wyników sieci, tzw. logitów. Cel tej operacji jest dwojaki:
- Podnosimy dysproporcje między poszczególnymi wynikami. Im wyższa wartość, tym bardziej zostaje zwielokrotniona.
- Pozbywamy się wartości mniejszych lub równych zero
Na końcu normalizujemy wyniki tj. dzielimy je przez ich sumę. Dzięki temu uzyskujemy rozkład prawdopodbieństwa z wartościami z zakresu 0-1. Z matematycznego punktu widzenia w ostatecznym wyniku funkcji softmax nigdy nie powinny pojawić się zera ani jedynki. W praktyce – ze względu na ograniczoną precyzję liczb zmiennnoprzecinkowych – możemy je czasami otrzymać. Skoro jesteśmy już przy tym temacie, warto też wspomnieć, podczas treningu zazwyczaj używamy zlogarytmowanej wersji funkcji softmax (LogSoftmax, log_softmax). Cechuje się ona po prostu lepszą stabilnością numeryczną.

Wracając do dysproporcji – zobaczmy co się stanie, jeśli cały wektor pomnożymy przez pewną liczbę > 1. O ile odległosci pomiędzy poszczegónymi wartościami logitów wzrosły proporcjonalnie, o tyle różnice w rozkładzie drastycznie się zmieniły. Na tym właśnie opiera się sterowanie temepraturą.

Temperatura
Mechanizm temperatury, zapożyczony ze mechaniki statystycznej (dział fizyki) wykorzystuje bardzo prosty trik. Zanim potraktujemy logity funkcją wykładniczą, dzielimy je wszystkie przez pewną wartość, zwykle oznaczną jako θ bądź T.
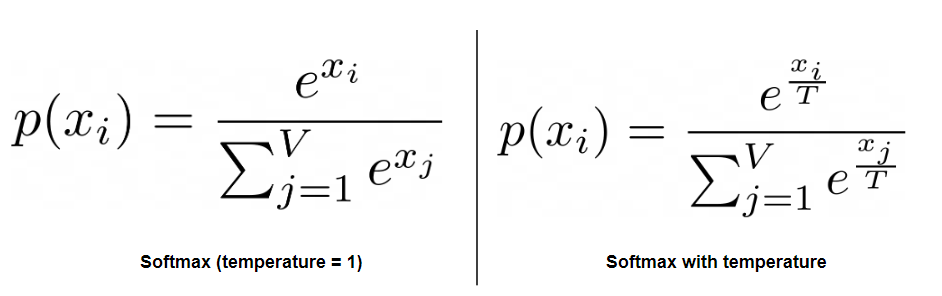
W zależności od wybranej wartości T, zachowanie naszego modelu będzie się zmieniać (polecam pobawić się suwakiem na tej stronie).
| T > 1 | Zmniejszamy dysproporcje między prawdopodobieństwami różnych tokenów. Zwiększa się szansza na niespodziewany wynik. |
| T = 1 | Nic się nie zmienia 🙂 |
| 0 < T < 1 | Dzielenie przez ułamek zwiększa wartości logitów. Im mniejsze T, tym bardziej wyróżniamy najwyższą wartość. Odpowiedzi stają się przewidywalne. |
| T = 0 | Nie możemy dzielić przez zero (ale jeśli T → 0, to dysproporcje → ∞). Standardowo oznacza to greedy sampling (pełny determinizm). |
| T < 0 | Zazwyczaj niedozowolone w interfesjach LLM-ów. W praktyce można to policzyć: ostatnie tokeny stają się pierwszymi (odwraca się rozkład). |
Top-k i top-p
Top-k i top-p to inne dwie metody służące do kontrolowania losowości w odpowiedziach modelu. Tym razem, zamiast modyfikować logity będziemy ograniczać nasz końcowy wybór do najbardziej prawdopodobnych odpowiedzi. W top-k wybieramy k najlepszych (najbardziej prawdopodobnych) opcji, natomiast w top-p (inaczej: nucleus sampling) wybieramy tyle możliwości, ile kumulatywnie da nam żądaną wartość p. Po ograniczeniu puli tokenów w ten sposób, skalujemy prawdopodobieństwa, aby sumowały się do 1 (100%). Metodę tę możemy rzecz jasna łączyć z mechanizmem temperatury.
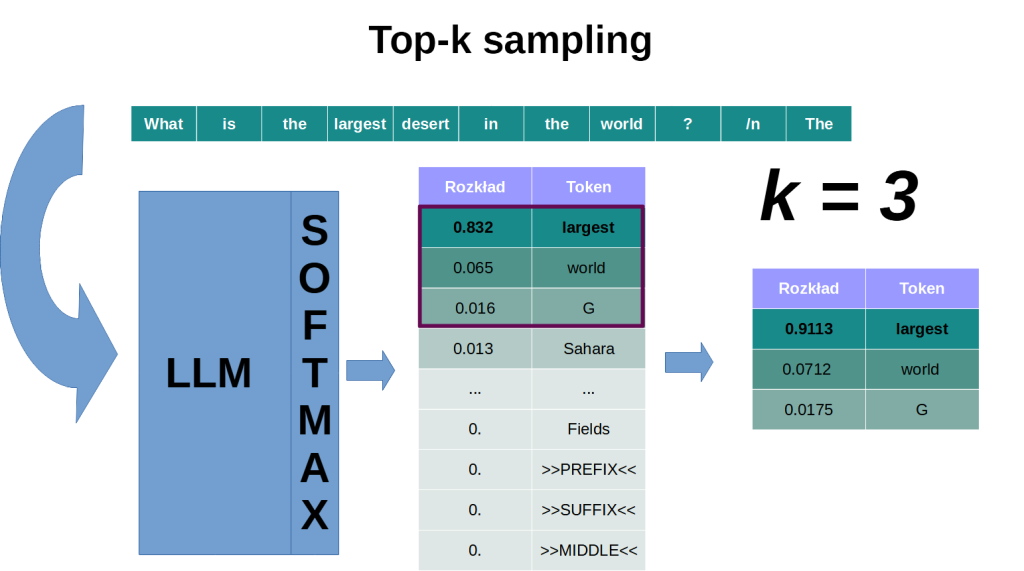
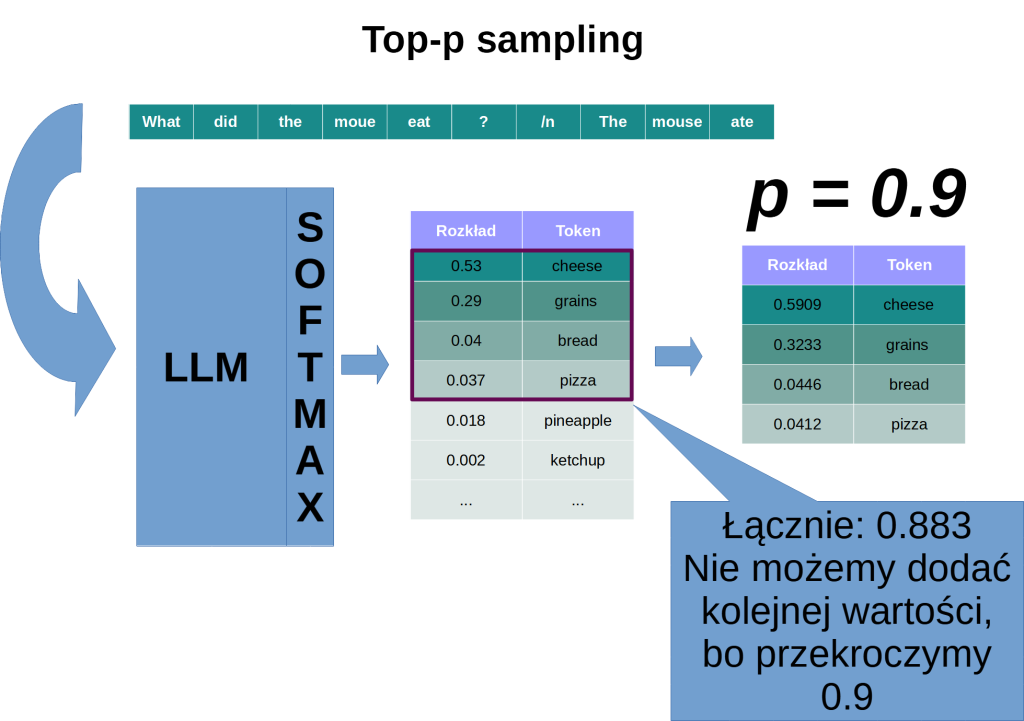
Beam search
Jak zauważyliśmy na początku artykułu, każdy wybrany token ma wpływ na wszystkie następne. Tym samym, wszystkie możliwości tworzą strukturę rozgałęziającą się na kształt drzewa. Zupełnie jak w grach, jak np. w szachy. Nasze aktualne posunięcie determinuje też przyszłe ruchy. Musimy więc myśleć zawsze wiele kroków do przodu. Celem jest uzyskanie mata, a nie szybkie zbicie piona. Analogiczne, jeśli chcemy skupić się na prawodpodobieństwie całej wypowiedzi, skorzystajmy z beam search – algorytmu do przeszukiwania grafów.
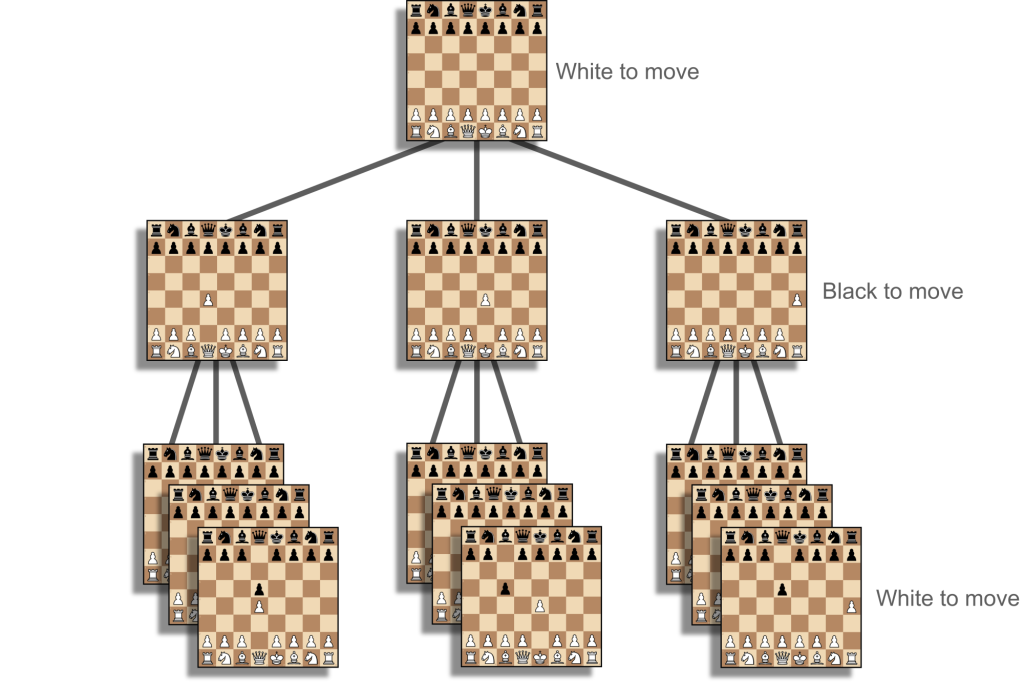
Drzewo gry dla przykładowej partii szachów. W przypadku gier typowym podejściem do trenowania modelu jest uczenie przez wzmacnianie. Co ciekawe, LLM-y czytają też teksty o szachach, więc czasem są w stanie w nie zagrać.
W każdym kroku zawężamy wybór do n najbardziej prawdopodbnych tokenów, uzyskując n rozgałęzień (patrz np. biblioteka Transformers – zmienna pod nazwą num_beams). Następnie liczymy prawdopodobieństwo dla każdej ze ścieżek i na tej podstawie opieramy swoje wybór. Metoda ta wymaga rzecz jasna więcej obliczeń, ale zapewnia dokładniejszą eksplorację przestrzeni wyników.
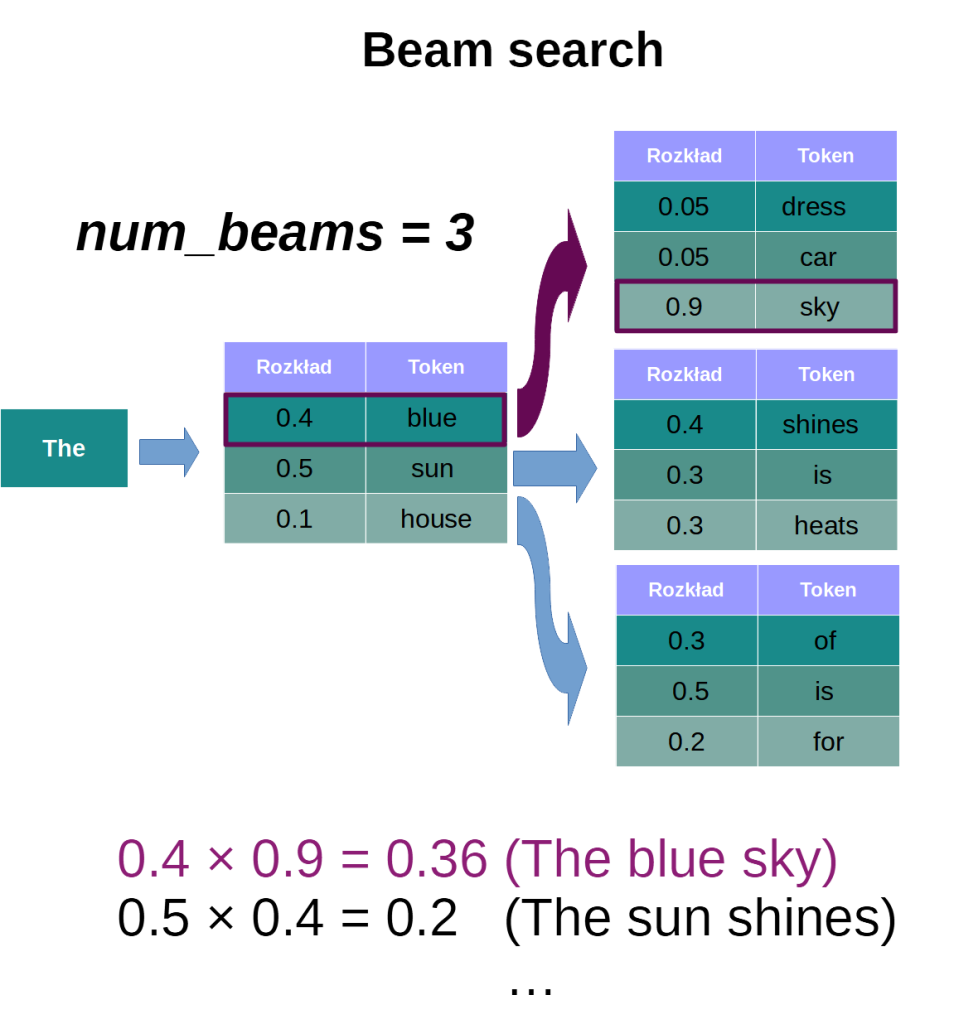
Jak widać na powyższym obrazku, gdybyśmy w pierwszym kroku wybrali token o najwyższym prawdopodbieństwie, wyegenrowalibyśmy ciąg The sun shines. Całkowite prawdopodobieństwo (uzyskane przez mnożenie) jest jednak wyższe dla sekwencji The blue sky.
Prompt engineering
Gdy zależy nam na okiełznaniu wybujałej fantazji modelu, możemy najzwyczajniej w świecie sterować nim poprzez wejście. Na tym właśnie opiera się dziedzina, którą po polsku nazwalibyśmy inżynierią zapytań (eng. prompt engineering). Oczywiście, nie zmierzam w krótkim akapicie streszczać wszystkich technik wypracowanych przez praktyków z branży. Przytoczę jednak kilka przykładów. Do podstaw tego cyfrowego rzemiosła należy precyzyjne formułowanie zapytań oraz podawanie przykładów i wzorów odpowiedzi. Dzięki temu model nie musi sam zgadywać, w jakiej formie chcielibyśmy otrzymać wynik.

Przykład ze strony DigitalOcean
Jeżeli chcemy pobudzić model do pewnej twórczości, zamiast manipulowac temeperaturą możemy napisać zapytanie o tej samej treści na kilka różnych sposobów. Ustawienie przy tym temperatury zero w zamyśle powinno nas ustrzec od przesadnych halucynacji, natomiast różnice w promptach przełożą się na różnorodność odpowiedzi.
Wśród bardziej finezyjnych metod znajdziemy Chain-of-Thought (CoT) oraz jej rozwinięcia: Tree-of-Thoughts (ToT) i Graph-of-Thoughts (GoT). Polegają one, w skrócie, na zmuszeniu modelu do przeprowadzenia “rozumowania” w kilku krokach. Trochę tak, jak uczy się matematyki w szkole podstawowej – rozpisz rozwiązanie, zamiast od razu podawać wynik. Notabene, w publikacjach dotyczących tych metod zauważamy, że często są one walidowane właśnie na zadaniach matematycznych.
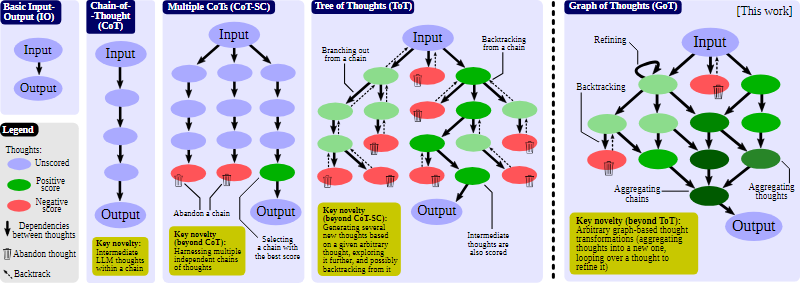
Kolejnymi koncepcjami, które można przypisać do tego samego nurtu są chociażby ToT Prompting (idea podobna do tej z Tree-of-Thoughts, ale skompresowana do jednego zapytania) czy pomysł na tworzenie dyskusji panelowych między modelami. Rzecz jasna, te kilka przykładów nie wyczerpuje tematu, gdyż ta dziedzina dynamicznie sie rozwija.
Bibliografia
- Cohere, LLM Parameters Demystified: Getting The Best Outputs from Language AI, 2022
- Yedidia A., SmartyHeaderCode: anomalous tokens for GPT3.5 and GPT-4, 2023
- Ouyang Sh., Zhang J.M., Harman M. i Wang M., LLM is Like a Box of Chocolates: the Non-determinism of ChatGPT in Code Generation, 2023
- Llama 2 – dokumentacja na Hugging Face
- MPT-30B – dokumentacja na Hugging Face
- Glover E., Controlled Randomness in LLMs/ChatGPT with Zero Temperature: A Game Changer for Prompt Engineering (substack.com), 2023
- OpenAI, How to count tokens with tiktoken (Jupyter Notebook), 2023
- Cameron R. Wolfe – Wpis na Twitterze na temat LLMów
- How to generate text: using different decoding methods for language generation with Transformers (huggingface.co) (Beam search)
- Besta M. in in., Graph of Thoughts: Solving Elaborate Problems with Large Language Models , 2023
- Luke Salamone, What is Temperature in NLP?
- LLM Reasoners – Biblioteka języka Python do zaawansowanego wnioskowania za pomocą dużych modeli językowych
- Christopher King, Proposal: Using Monte Carlo tree search instead of RLHF for alignment research
- Derek Kauffman (Cavendish Blueprints), Sampling at negative temperature, 2023
- DigitalOcean, Prompt Engineering Best Practices: Tips, Tricks, and Tools (dostęp: wrzesień 2024)
- Prompt Engineering Guide, Tree of Thoughts (ToT), (dostęp: wrzesień 2024)

Dzięki Krzysztof, detaliczny artykuł, dużo pracy, ładne grafiki, liczna bibliografia i zrozumiała treść.
Pozdrawiam